.")
 HKUST CSE PhD
HKUST CSE PhDHi! I am Bingnan Chen (陈炳楠), a Ph.D. student in Computer Science and Engineering at the Hong Kong University of Science and Technology (HKUST), where I also completed my MPhil degree.
Prior to that, I received my bachelor's degree from the University of Science and Technology of China (USTC).
My research interests focus on database optimization algorithms, query processing and query optimization under the supervision of Prof. Ke Yi.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
The Hong Kong University of Science and TechnologyDepartment of Computer Science and Engineering
Ph.D. StudentSep. 2023 - present -
The Hong Kong University of Science and TechnologyDepartment of Computer Science and Engineering
MPhil. StudentSep. 2021 - Jul. 2023 -
 University of Science and Technology of ChinaB.S. in Computer ScienceSep. 2017 - Jul. 2021
University of Science and Technology of ChinaB.S. in Computer ScienceSep. 2017 - Jul. 2021
Experience
-
 Alibaba CloudResearch Intern (Database Group)Aug. 2023 - Feb. 2024
Alibaba CloudResearch Intern (Database Group)Aug. 2023 - Feb. 2024 -
 SensetimeResearch InternJan. 2021 - Jul. 2021
SensetimeResearch InternJan. 2021 - Jul. 2021
Selected Publications (view all )
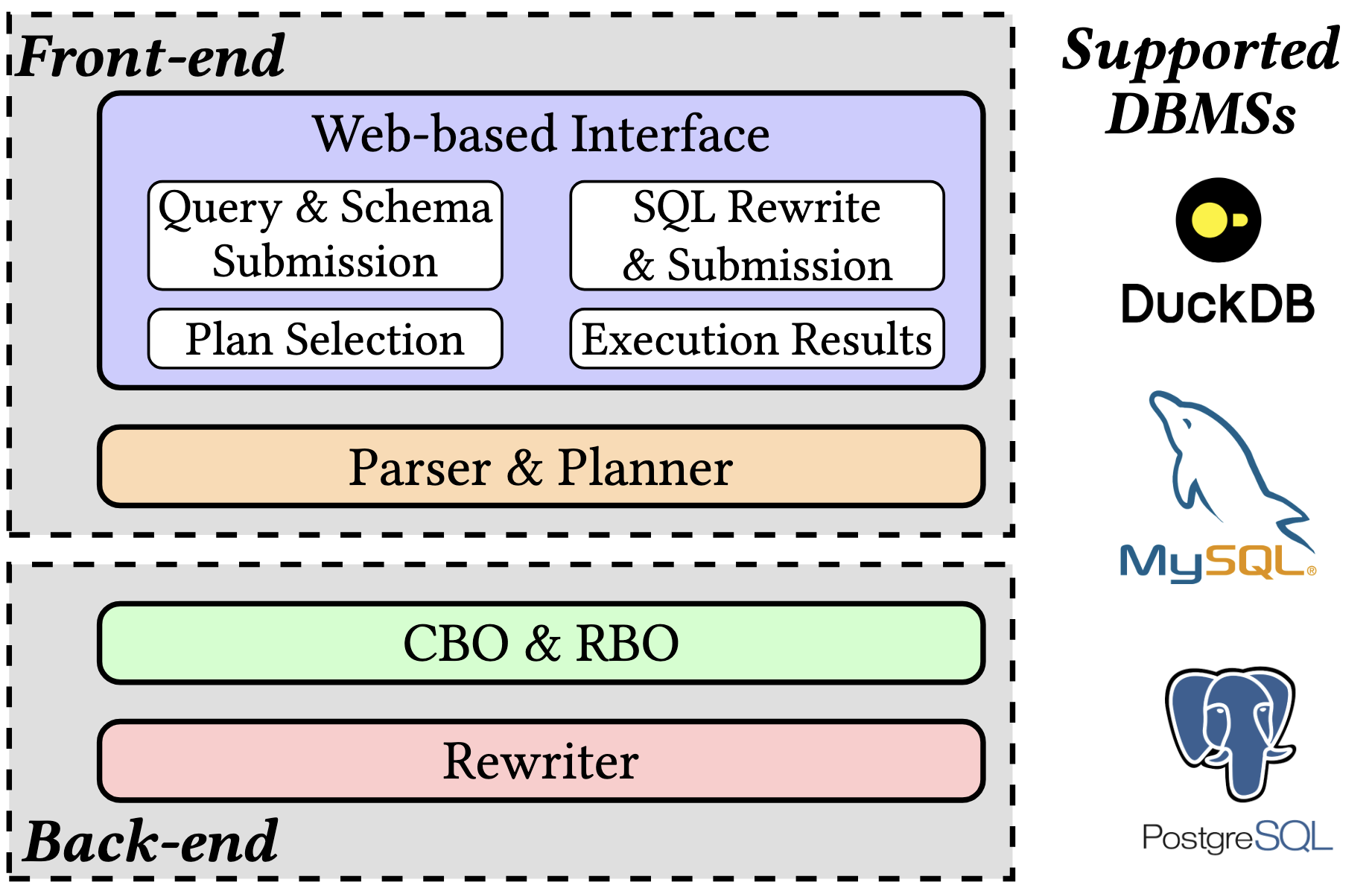
Query Running Too Slow? Rewrite it with Quorion!
Bingnan Chen, Binyang Dai, Qichen Wang, Ke Yi
Proceedings of the VLDB Endowment, Volume 18, Issue 12, Pages 5243 - 5246 2025
We will demonstrate Quorion, a query rewriter with theoretical guarantees and better practical performance. Quorion adopts some of the recently developed query planning methods that provide optimality guarantees, including Yannakakis+, an optimized version of the Yannakakis algorithm, generalized hypertree decompositions (GHD), GYO reduction, and cost-based optimization. Quorion also provides a platform for users to explore different query plans for a given query through a web-based interface and compare their performance with classical query plans. Quorion currently supports DuckDB, MySQL, and PostgreSQL, and can be connected to any user-provided database easily through a JDBC connector.
Query Running Too Slow? Rewrite it with Quorion!
Bingnan Chen, Binyang Dai, Qichen Wang, Ke Yi
Proceedings of the VLDB Endowment, Volume 18, Issue 12, Pages 5243 - 5246 2025
We will demonstrate Quorion, a query rewriter with theoretical guarantees and better practical performance. Quorion adopts some of the recently developed query planning methods that provide optimality guarantees, including Yannakakis+, an optimized version of the Yannakakis algorithm, generalized hypertree decompositions (GHD), GYO reduction, and cost-based optimization. Quorion also provides a platform for users to explore different query plans for a given query through a web-based interface and compare their performance with classical query plans. Quorion currently supports DuckDB, MySQL, and PostgreSQL, and can be connected to any user-provided database easily through a JDBC connector.

Yannakakis+: Practical Acyclic Query Evaluation with Theoretical Guarantees
Qichen Wang*, Bingnan Chen*, Binyang Dai, Ke Yi, Feifei Li, Liang Lin (* equal contribution)
Proceedings of the ACM on Management of Data, Volume 3, Issue 3, Article No.: 235, Pages 1 - 28 2025
Acyclic conjunctive queries form the backbone of most analytical workloads, and have been extensively studied in the literature from both theoretical and practical angles. However, there is still a large divide between theory and practice. While the 40-year-old Yannakakis algorithm has strong theoretical running time guarantees, it has not been adopted in real systems due to its high hidden constant factor. In this paper, we strive to close this gap by proposing Yannakakis+, an improved version of the Yannakakis algorithm, which is more practically efficient while preserving its theoretical guarantees. Our experiments demonstrate that Yannakakis+ consistently outperforms the original Yannakakis algorithm by 2x to 5x across a wide range of queries and datasets. Another nice feature of our new algorithm is that it generates a traditional DAG query plan consisting of standard relational operators, allowing Yannakakis+ to be easily plugged into any standard SQL engine. Our system prototype currently supports four different SQL engines (DuckDB, PostgreSQL, SparkSQL, and AnalyticDB from Alibaba Cloud), and our experiments show that Yannakakis+ is able to deliver better performance than their native query plans on 160 out of the 162 queries tested, with an average speedup of 2.41x and a maximum speedup of 47,059x.
Yannakakis+: Practical Acyclic Query Evaluation with Theoretical Guarantees
Qichen Wang*, Bingnan Chen*, Binyang Dai, Ke Yi, Feifei Li, Liang Lin (* equal contribution)
Proceedings of the ACM on Management of Data, Volume 3, Issue 3, Article No.: 235, Pages 1 - 28 2025
Acyclic conjunctive queries form the backbone of most analytical workloads, and have been extensively studied in the literature from both theoretical and practical angles. However, there is still a large divide between theory and practice. While the 40-year-old Yannakakis algorithm has strong theoretical running time guarantees, it has not been adopted in real systems due to its high hidden constant factor. In this paper, we strive to close this gap by proposing Yannakakis+, an improved version of the Yannakakis algorithm, which is more practically efficient while preserving its theoretical guarantees. Our experiments demonstrate that Yannakakis+ consistently outperforms the original Yannakakis algorithm by 2x to 5x across a wide range of queries and datasets. Another nice feature of our new algorithm is that it generates a traditional DAG query plan consisting of standard relational operators, allowing Yannakakis+ to be easily plugged into any standard SQL engine. Our system prototype currently supports four different SQL engines (DuckDB, PostgreSQL, SparkSQL, and AnalyticDB from Alibaba Cloud), and our experiments show that Yannakakis+ is able to deliver better performance than their native query plans on 160 out of the 162 queries tested, with an average speedup of 2.41x and a maximum speedup of 47,059x.
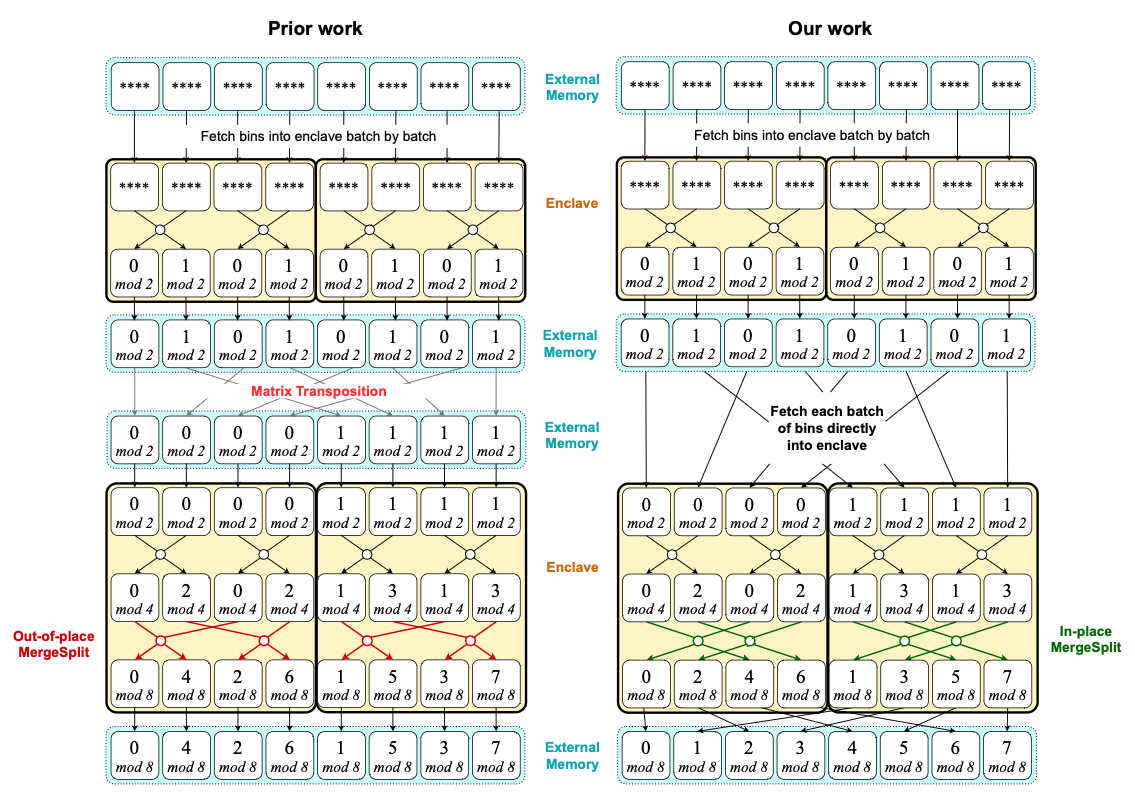
Flexway O-Sort: Enclave-Friendly and Optimal Oblivious Sorting
Tianyao Gu, Yilei Wang, Afonso Tinoco, Bingnan Chen, Ke Yi, Elaine Shi
Usenix Security Symposium (USENIX Security) 2025
Oblivious algorithms are being deployed at large scale in real world to enable privacy-preserving applications such as Signal’s private contact discovery. Oblivious sorting is a fundamental building block in the design of oblivious algorithms for numerous computation tasks. Unfortunately, there is still a theory-practice gap for oblivious sort. The commonly implemented bitonic sorting algorithm is not asymptotically optimal, whereas known asymptotically optimal algorithms suffer from large constants. In this paper, we construct a new oblivious sorting algorithm called flexway o-sort, which is asymptotically optimal, concretely efficient, and suitable for implementation in hardware enclaves such as Intel SGX. For moderately large inputs of 12 GB, our flexway o-sort algorithm outperforms known oblivious sorting algorithms by 1.32x to 28.8x when the data fits within the hardware enclave, and by 4.1x to 208x when the data does not fit within the hardware enclave. We also implemented various applications of oblivious sorting, including histogram, database join, and initialization of an ORAM data structure. For these applications and data sets from 8GB to 32GB, we achieve 1.44∼2.3x speedup over bitonic sort when the data fits within the enclave, and 4.9∼5.5x speedup when the data does not fit within the enclave.
Flexway O-Sort: Enclave-Friendly and Optimal Oblivious Sorting
Tianyao Gu, Yilei Wang, Afonso Tinoco, Bingnan Chen, Ke Yi, Elaine Shi
Usenix Security Symposium (USENIX Security) 2025
Oblivious algorithms are being deployed at large scale in real world to enable privacy-preserving applications such as Signal’s private contact discovery. Oblivious sorting is a fundamental building block in the design of oblivious algorithms for numerous computation tasks. Unfortunately, there is still a theory-practice gap for oblivious sort. The commonly implemented bitonic sorting algorithm is not asymptotically optimal, whereas known asymptotically optimal algorithms suffer from large constants. In this paper, we construct a new oblivious sorting algorithm called flexway o-sort, which is asymptotically optimal, concretely efficient, and suitable for implementation in hardware enclaves such as Intel SGX. For moderately large inputs of 12 GB, our flexway o-sort algorithm outperforms known oblivious sorting algorithms by 1.32x to 28.8x when the data fits within the hardware enclave, and by 4.1x to 208x when the data does not fit within the hardware enclave. We also implemented various applications of oblivious sorting, including histogram, database join, and initialization of an ORAM data structure. For these applications and data sets from 8GB to 32GB, we achieve 1.44∼2.3x speedup over bitonic sort when the data fits within the enclave, and 4.9∼5.5x speedup when the data does not fit within the enclave.